
What will it take to build general-purpose robots? Machines that don’t just vacuum the floor or pick a single object but can adapt to a wide range of tasks in homes, warehouses, and hospitals. In 2025, it seems we stand on the cusp of robotic transformation, but there’s still a fundamental question: how do we get there?
This article draws from a talk I gave at RSS 2025, exploring a powerful idea that has reshaped natural language processing and computer vision: scaling laws. Can they do the same for robotics?
One of the most striking challenges is the data gap. π0, one of the most prominent robotic foundation models, was trained on roughly 10,000 hours of demonstrations. In contrast, large language models like Quen-2.5 have likely been trained on over 1.2 billion hours of text. That’s a 100,000-fold difference [source]. It highlights one of the most profound bottlenecks facing robotics today: data scarcity. Not just in quantity, but also in quality and diversity. If language models need internet-scale data, what does that mean for embodied intelligence?
Fortunately, we have a potential framework to reason about that: neural scaling laws.
Scaling laws describe how performance changes as we increase inputs like model size, data, or compute. These relationships typically follow power laws, and they’re ubiquitous across science. In biology, an animal’s metabolic rate scales to the 3/4 power of its mass. In geophysics, the frequency of earthquakes scales with their magnitude. In venture capital, startup returns follow heavy-tailed distributions. More than 100 such scaling phenomena have been documented across domains, and AI is no exception.
In machine learning, scaling laws suggest that we can predict performance if we know the amount of data, model parameters, and compute budget. These predictions are surprisingly robust. Since 2017, researchers such as Jonathan Rosenfeld at MIT and teams at Baidu have demonstrated that increasing certain resources leads to predictable, diminishing returns in loss or accuracy. This insight was transformative. The 2020 OpenAI paper by Kaplan et. al introduced the term "neural scaling laws" and showed that performance improves as a power function of compute, model size, or dataset size [source]. The findings were refined further by DeepMind in 2022, who showed that scaling model and data size in tandem, in the right ratio, leads to optimal efficiency, a result known as the Chinchilla law [source].
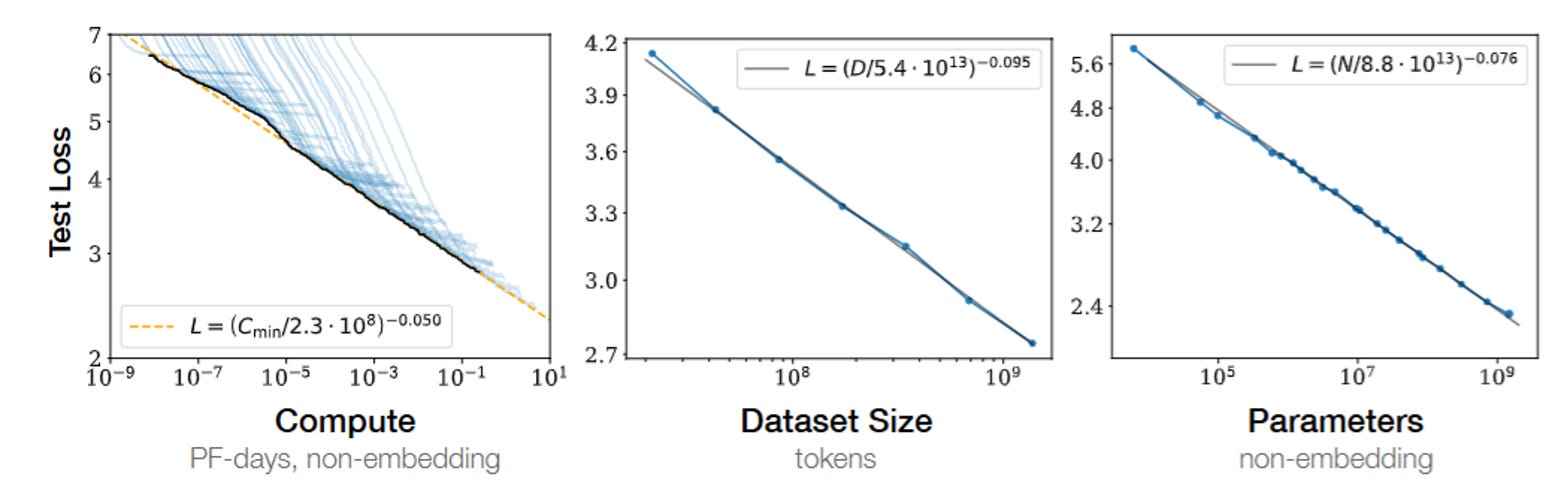
Why does this matter for robotics? Because it suggests we might be able to answer the most important questions of robotic generalization: how much data is enough? How big must our models be? And how far can we push current architectures before hitting hard constraints?
Until recently, we didn’t know. But the field has started to change. In 2024 and 2025, the first systematic studies of scaling laws in robotics emerged. We now have initial results showing that, yes, scaling data and model size improves performance in robot learning, but the story is far from complete.
In a meta-analysis with 327 papers I performed, only 26 explored data size scaling in any systematic way. Most compared just two sizes, limiting the reliability of conclusions. Even fewer studied compute scaling. Still, for the papers that did quantify scaling laws, performance gains were observed, with scaling exponents for data and model size ranging from -0.01 to as high as -1.0. That’s a wide range, reflecting the diversity of robotics tasks. Some models improve rapidly with scale; others plateau early. In aggregate, we see a median exponent of around -0.217 for data and -0.172 for model size [source]. These numbers are encouraging.
But how does robotics compare to other fields? The scaling efficiency varies per domain. For instance, a 8x8 pixel vision model needs a 40-fold increase in compute to double performance. Language models are far more costly requiring nearly two million times more compute to achieve a 2x improvement. Robotics falls somewhere in the middle. According to current estimates, doubling robot performance might require 24 times more data, 56 times larger models, and 736 times more compute. It’s less efficient than vision, but significantly more so than language.
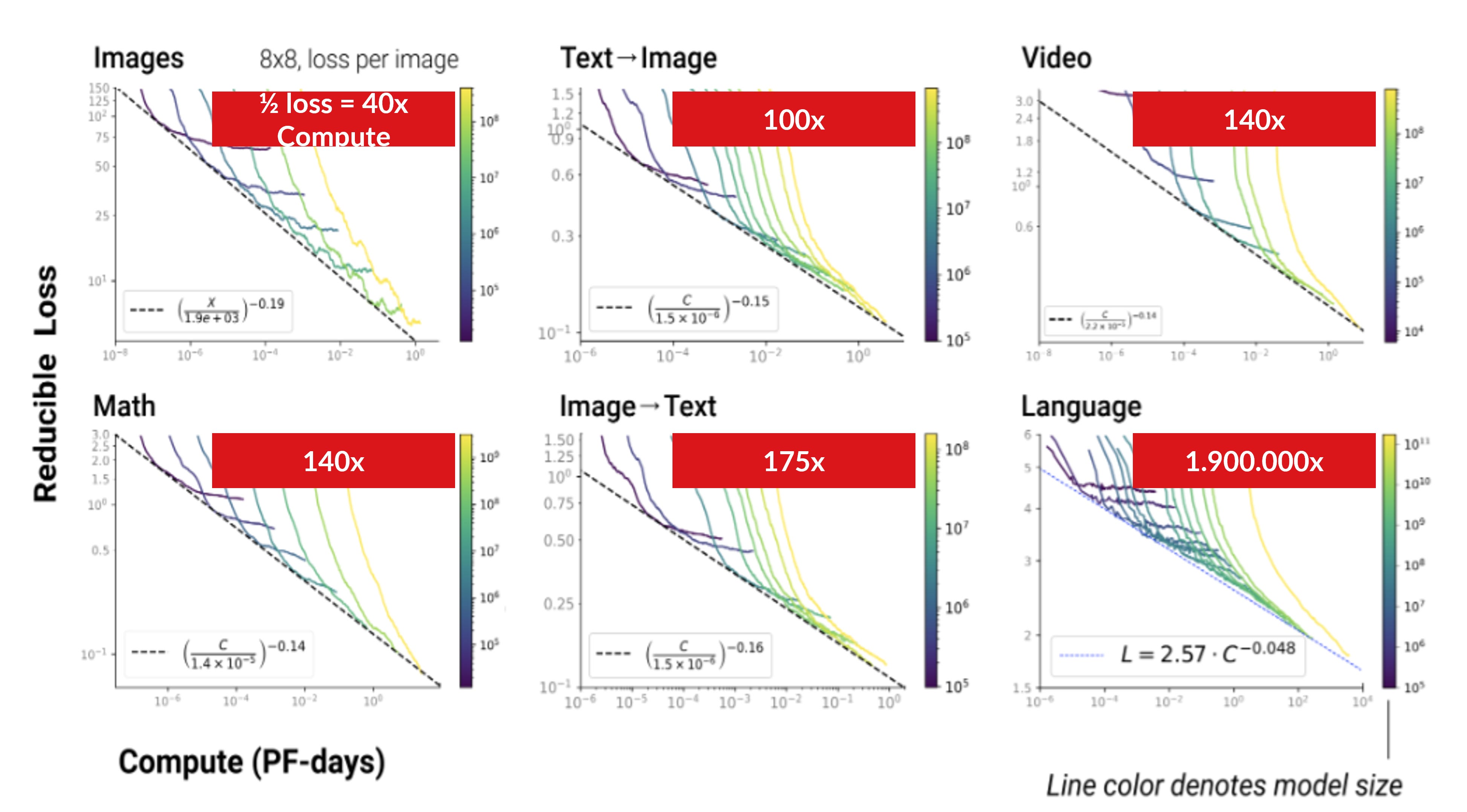
The inefficiency in language arises from its high entropy and the sparsity of useful signal across tokens. Robotics, by contrast, often benefits from dense perceptual input, especially in vision, where each frame or sensor reading can carry rich, structured information. That said, robotics introduces its own inefficiencies: noisy real-world data, multimodal complexity, and the difficulty of long-horizon control. Moreover, there are many valid solutions to the same task, unlike language where outputs tend to converge.
Data in robotics is not just a matter of hours or tokens. It involves diversity across multiple axes: the number of tasks, objects, environments, and embodiments. A dataset of a million demonstrations from one task is less valuable than a dataset of 100,000 demonstrations spanning 100 tasks. This makes scaling complex.
Compounding the challenge is hardware. Robots don’t just run inference like cloud-hosted models. They interact with the real world in real time. That imposes constraints on memory, power, latency, and heat dissipation. Papers are already reporting that they cannot scale models further due to inference latency [source]. Some propose offloading to the cloud; others suggest action chunking or lightweight architectures. But the problem remains: unlike text generation, real-world behavior must be fast, safe, and reliable.
This raises the question: will robotics have its own ChatGPT moment?
Probably not in the same way. ChatGPT succeeded because it was instantly accessible, surprisingly capable, and broadly relatable. You could share it with a link. Robots are different. They require hardware, calibration, safety protocols, and real-world deployment. Even if we built a general-purpose robotic brain tomorrow, most people wouldn’t be able to use it [source].
Still, that doesn’t mean progress will be slow. If we can learn from NLP and vision, we can accelerate robotic development significantly. But we need rigorous science: empirical scaling studies, benchmarking of scaling exponents, and model architectures optimized for multimodal, real-world interaction. Early signs are promising. But we’re just beginning to chart this territory.
It is also important to remember that scaling has downsides. Environmental cost is growing. Centralization of power in a few labs increases inequality. Diminishing returns make each additional gain more expensive. And safety concerns loom large, especially when models control physical machines.
So what should the robotics community do?
First, we need to move from shallow ablation studies to real scaling research. That means measuring not just task performance, but also scaling efficiency. It means reporting exponents, not just success rates. It means experimenting with data diversity, simulation, teleoperation, and real-world data collection at scale. Second, we should explore pretraining-focused scaling. While test-time adaptation is important, pretraining is where we get the biggest return on investment right now. Third, we must prepare for misbehavior. Just as language models hallucinate, robots will make mistakes, and some could be dangerous. We need to measure and mitigate these behaviors early.
Finally, we must invest in the science of scaling laws for robotics. That includes understanding how hardware constraints shape architectural choices, how embodiment influences generalization, and how to benchmark across diverse task spaces. As Ted Xiao put it: if we froze today’s algorithms and just scaled compute and money, it wouldn’t be enough to solve robotics. We need better tools, better methods, and better science.
The future of robotics will not be built by accident. It will be built by understanding. Scaling laws give us the roadmap. Let’s use it.
And if you’re working on this, I’d love to hear from you. We’re building the foundations of this field now. Every experiment matters.
Just learned that Bell Labs already found neural scaling laws in 1993 and that scaling laws have a much older history than I thought. Here's the link to the NeurIPS paper: https://proceedings.neurips.cc/paper/1993/file/1aa48fc4880bb0c9b8a3bf979d3b917e-Paper.pdf
Hey, cool post! If I only read one of the papers analyzing scaling laws for robotics, which one should I read? Also, you look at the reduction in loss for the scaling laws. Does a 50% reduction in loss necessarily also transfer to the same improvement in accuracy/success rate in the respective domains? That would be the obvious metric that matters.